- Alphawise
- Posts
- 2024-12-27
2024-12-27
DeepSeek, a new top 5 model
Matthew McCann
December 27, 2024

A technical AI newsletter - written with an entrepreneurial spirit for builders
Welcome to your daily newsletter on AI
What have we got for you today?
DeepSeek - a new LLM in the Top 5
MoE (mixture of experts) - Origin story and explanation
Haystack tutorial - RAG pipeline in 2 minutes
We are 100% free!
And with your support, we create more FREE content!
Please share with a friend, or 10!
🎯 RELEASES 🎯
Bringing insights into the latest trends and breakthroughs in AI
DeepSeek
A new LLM in Top 5
Synopsis
DeepSeek has unveiled DeepSeek-V3, an open-source language model featuring 671 billion parameters, with 37 billion activated per token. This model employs a Mixture-of-Experts (MoE) architecture, enhancing efficiency by activating only task-relevant parameters. Trained on 14.8 trillion high-quality tokens, DeepSeek-V3 demonstrates performance on par with leading closed-source models like GPT-4o and Claude 3.5 Sonnet, marking a significant advancement in the open-source AI landscape.
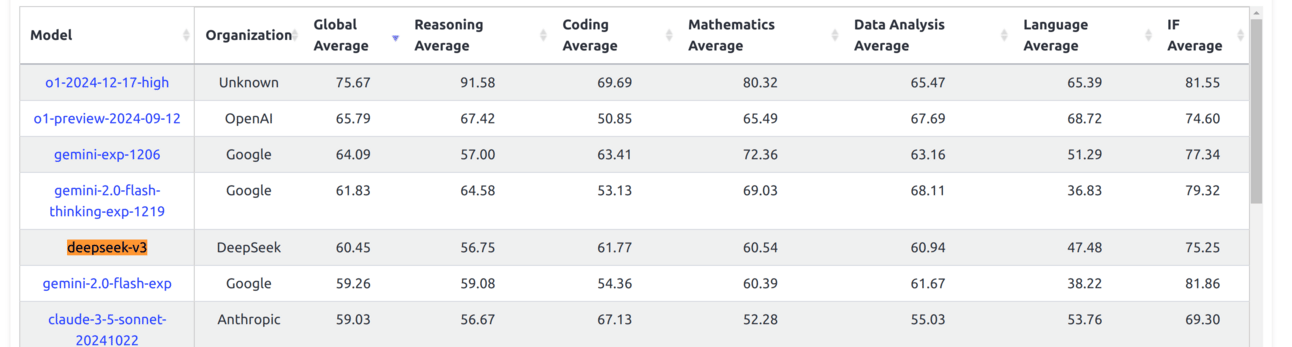
DeepSeek in position #5, www.livebench.ai
Core Observations
Advanced Mixture-of-Experts Architecture: the model activates specific subsets of its parameters tailored to each task to optimise computational efficiency and performance.
Superior Benchmark Performance: a score of 90.2 on the MATH-500 test. View other benchmarks here.
Enhanced Training and Inference Efficiency: Innovations such as an auxiliary loss-free load-balancing strategy and multi-token prediction training objectives contribute to model processing up to 60 tokens per second.
Broader Context
DeepSeek-V3, an open-source Chinese organisation, demonstrates that not only the big tech companies can achieve results; the open-source models can rival, and in some cases surpass, the capabilities of closed-source alternatives. Moreover, the cost-effective API pricing of DeepSeek-V3, set at $0.14 per million input tokens and $0.28 per million output tokens (matching OpenAI’s costs) gives appeal for widespread adoption.
Article
Mixture of Experts - a common, modern framework
Synopsis
The Mixture of Experts (MoE) framework is an approach in large language model (LLM) development that dynamically activates only the most relevant subsets of a model's parameters for a given task. This technique, rooted in the seminal 1994 paper by Michael I. Jordan and Robert A. Jacobs, optimises computational efficiency and scalability, enabling leading AI providers like Google and OpenAI to develop powerful yet cost-effective models. MoE has reshaped the landscape of LLMs, providing significant advancements in performance, specialization, and resource utilization.
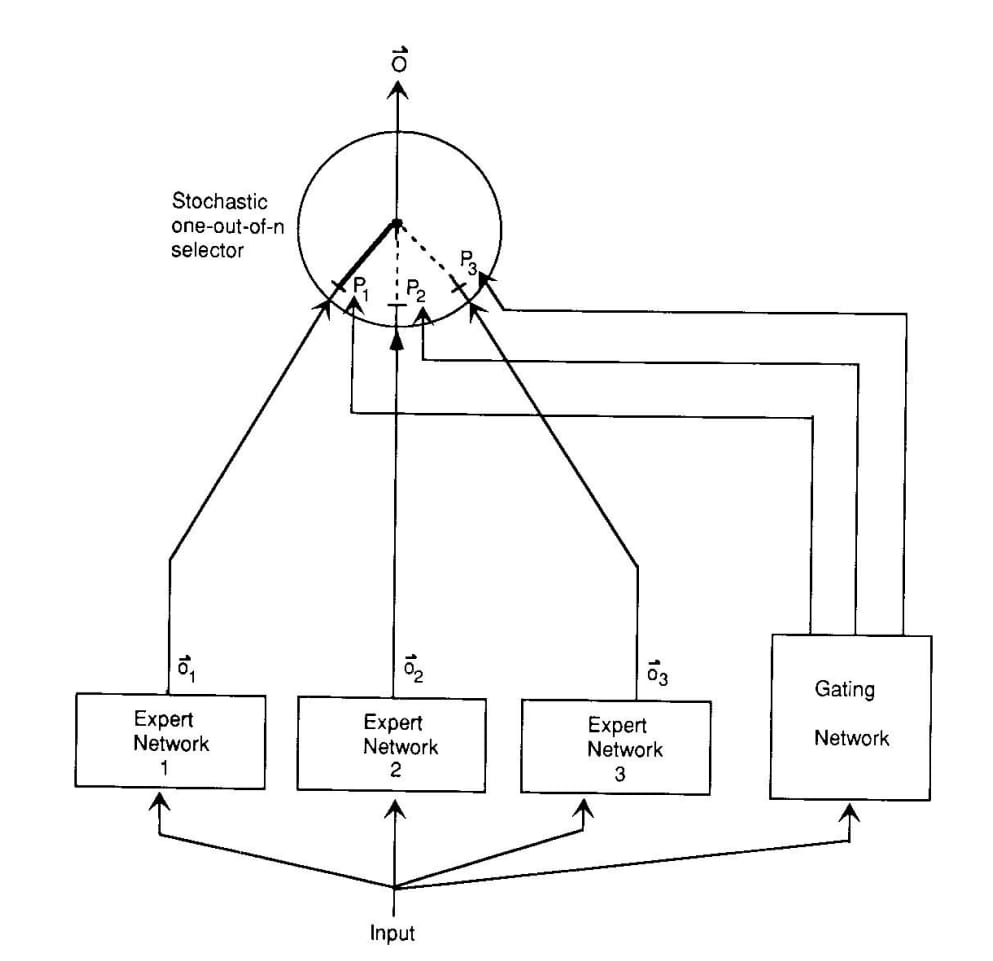
Core Observations
Dynamic Parameter Activation:
MoE models activate only a small portion of their parameters during inference (e.g., 1-5% of the total), reducing computational overhead without sacrificing accuracy.
This allows for models with hundreds of billions or even trillions of parameters to operate efficiently on smaller hardware.
Improved Scalability:
MoE enables the construction of ultra-large models like DeepMind's GLaM and Google’s Switch Transformer, which scale computational demands to match specific tasks.
These models outperform dense architectures in benchmarks while using fewer resources.
Specialization and Diversity:
MoE models consist of multiple expert sub-models, each specializing in a subset of tasks or domains, allowing for unparalleled adaptability and knowledge diversity.
This feature enhances performance in multitask and multilingual scenarios.
Adoption by Leading Providers:
Google and OpenAI employ MoE techniques in their next-generation LLMs to optimize large-scale deployments.
Hugging Face supports MoE frameworks, democratizing access to this architecture for developers worldwide.
Broader Context
Several cutting-edge AI models leverage the Mixture of Experts (MoE) approach to enhance performance and efficiency. Google's Switch Transformer is among the most notable implementation, and OpenAI is also reportedly experimenting with MoE techniques to improve the efficiency of its GPT-series models, particularly for specialized tasks. Additionally, DeepMind has adopted MoE frameworks in models such as Sparrow, aimed at safer and more efficient language reasoning.
Trending
⚙️ BUILDERS BYTES ⚙️
Informing builders of latest technologies and how to use them
Haystack - a 5 minute RAG pipeline!
What will you learn today?
Perhaps you have been exploring frameworks like LangChain, LlamaIndex, or AISuite to build maintainable code for an LLM application? Today we explore Haystack an open source AI framework. Today we will build a Retrieval-Augmented Generation (RAG) pipeline with Haystack, combining retrieval techniques to make a chat backend.
Key Takeaways
Integrate Retrieval and Generation: Use Haystack to combine search-based retrieval with generative AI for efficient Q&A systems.
Jupyter Notebook demo: Quick tutorial to set up a RAG pipeline using Python and pre-trained models.
Scalable Infrastructure: Discover tools to deploy scalable, production-ready RAG systems using Haystack.
Below is the basic building blocks to get started, but there is more:
👉️ view the full code
from haystack import Pipeline
basic_rag_pipeline = Pipeline()
# Add components to your pipeline
basic_rag_pipeline.add_component("text_embedder", text_embedder)
basic_rag_pipeline.add_component("retriever", retriever)
basic_rag_pipeline.add_component("prompt_builder", prompt_builder)
basic_rag_pipeline.add_component("llm", chat_generator)
# Connect the components to each other
basic_rag_pipeline.connect("text_embedder.embedding", "retriever.query_embedding")
basic_rag_pipeline.connect("retriever", "prompt_builder")
basic_rag_pipeline.connect("prompt_builder.prompt", "llm.messages")
# Ask a question
question = "What does Rhodes Statue look like?"
response = basic_rag_pipeline.run({"text_embedder": {"text": question}, "prompt_builder": {"question": question}})
# Show response
print(response["llm"]["replies"][0].text)We just wanted to show you a snippet for now. The full tutorial is available in our newsletter repo 👉️ code
Do you have a product in AI and would like to contribute?
👉️ email us: [email protected]
Is there something you’d like to see in this section?
👉️ share your feedback
Trending
🤩 COMMUNITY 🤩
Cultivating curiosity with latest in professional development
Tools
Learning
THANK YOU
Our Mission at AlphaWise
AlphaWise strives to cultivate a vibrant and informed community of AI enthusiasts, developers, and researchers. Our goal is to share valuable insights into AI, academic research, and software that brings it to life. We focus on bringing you the most relevant content, from groundbreaking research and technical articles to expert opinions to curated community resources.
Looking to connect with us?
We actively seek to get involved in community with events, talks, and activities. Email us at [email protected]